
 Alex Bloss
Alex Bloss- 06 Nov, 2023
Interactive Web-App with Streamlit: Web-UI for Chat-with-your-Documents
Using our chat class from the last post we now build a web-app with Streamlit for easy chat with your documents

In one of our previous posts , we built a simple chatbot with web-ui that can answer questions about a specific document. We used Retrieval-Augmented Generation (RAG) to ground our Large Language Model (LLM) in the document and generate answers to questions based on the facts mentioned in our document.
Grounding Large Language Models (LLMs) involve integrating specific data or context to provide more accurate, domain-specific responses, addressing the limitations of traditional LLMs like ChatGPT in generating precise answers. Retrieval-Augmented Generation (RAG) complements this by enabling LLMs to use external, domain-specific data for text generation, enhancing accuracy and context-awareness, thus bridging the gap between general language understanding and specialized expertise.
Chunking in natural language processing involves breaking text into small, meaningful segments for more efficient retrieval by RAG systems. The key is to find the right balance in chunk size: large enough to capture essential information but small enough to capture only one idea or concept at a time for precise semantic search and also to minimize processing time. Overlapping chunks can help balance these needs, ensuring enough relevant data is retrieved for contextually accurate responses.
The problem is, that the LLM needs a broader context to generate more informed and contextually rich responses. However, the chunk size for the embeddings should be smaller to optimize it for detailed, semantic analysis and efficient retrieval.
So let’s explore a possible strategy how we can solve this dilemma and improve our chatbot.
A document hierarchy enhances information retrieval in RAG systems by structuring data like a table of contents. It organizes chunks into a parent-child node system, with each node summarizing its content. This structure allows RAG systems to navigate and identify relevant chunks more precisely and efficiently.
We could also apply this concept to a system of multiple documents organized in a hierarchy. However, for our purposes, we will concentrate on organizing sections or “chunks” within a single document in a hierarchical manner.
So let’s take a closer look how we can use this idea at the scope of a single document.
LangChain implements this strategy with the ParentDocumentRetriever, which involves initially splitting documents into larger parent- and smaller child-chunks to ensure that the embeddings of the smaller child-chunks accurately reflect their specific content. However, to maintain context, it also retrieves the corresponding parent-chunk for each child-chunk as context for the LLM-question-answering.
This approach balances the need for precise meaning in embeddings with the necessity of retaining contextual information.
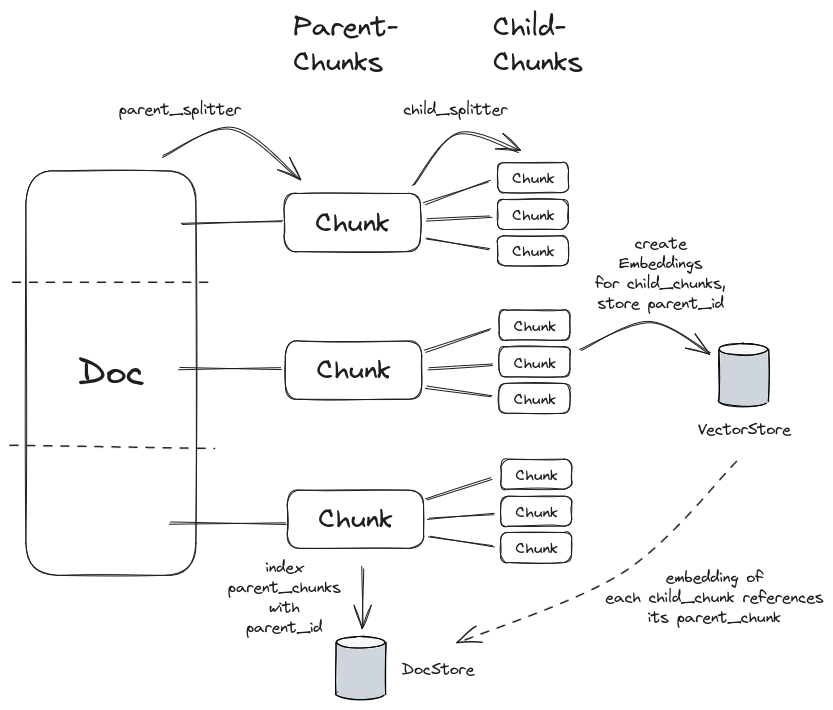
In the diagram above you can see the idea behind the mentioned strategy, where we split the document into parent and child chunks. The parent chunks are larger and contain more information, while the child chunks are smaller and contain less information. The child chunks are used for the retrieval phase (find semantically relevant information), while the parent chunks are used as context by the LLM in the generation phase.
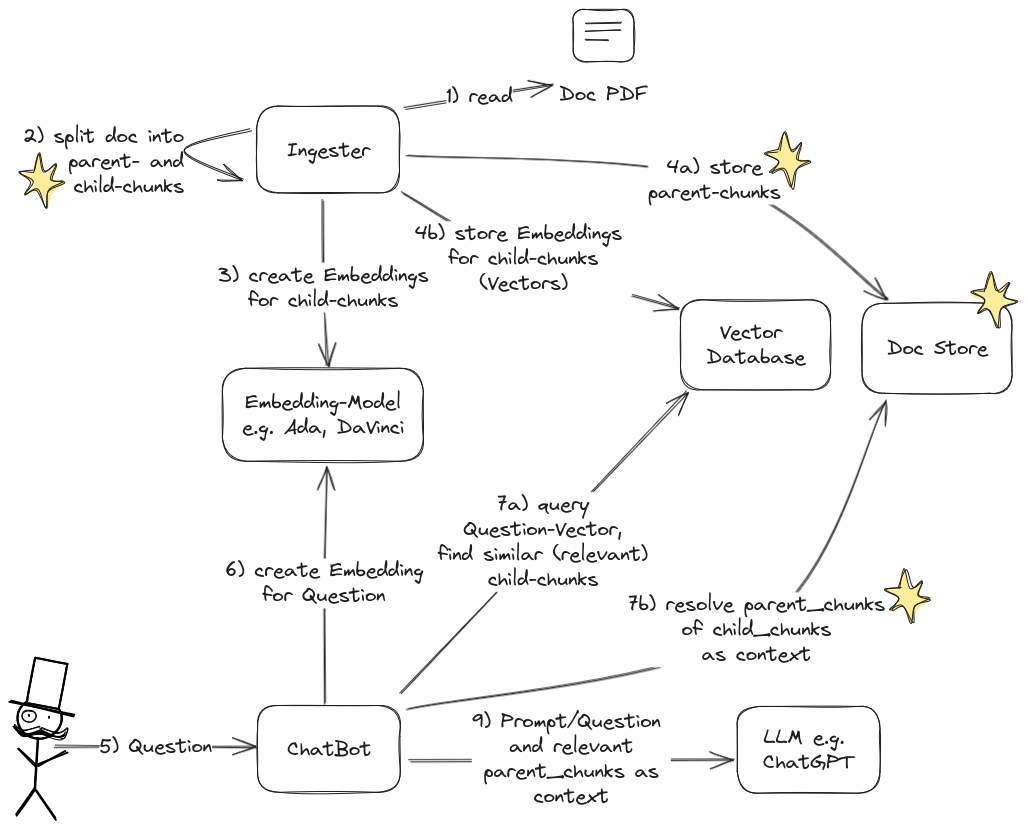
In resemblance to the original RAG-Flow, we adapted the flow to include the handling of the parent- and child-chunks. Changed flow-steps are marked with a star.
We have to change the code of our _load_and_process_document method of the DocChat-class,
that we built in this post
.
We are creating two distinct TextSplitter objects using the RecursiveCharacterTextSplitter class, each serving a different purpose in the Retrieval-Augmented Generation (RAG) process.
The code below shows how we can use the RecursiveCharacterTextSplitter class to create
parent and child chunks.
We still use the Chroma class to create a vector database for storing embeddings.
The parent docs are stored in an InMemoryStore object, which is a simple storage layer
that stores the parent chunks in memory.
@staticmethod
def _load_and_process_document(file: str, chain_type: str, k: int) -> (ConversationalRetrievalChain, int):
loader = PyPDFLoader(file)
documents = loader.load()
# This text splitter is used to create the larger parent chunks
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=100)
# This text splitter is used to create the smaller child chunks
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=50)
# Make sure that we forget the embeddings of previous documents
db = Chroma()
db.delete_collection()
# Vector-Database
db = Chroma(embedding_function=embeddings)
# The storage layer for the parent chunks
store = InMemoryStore()
# Create ParentDocumentRetriever, return `k` most similar chunks for each question
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
retriever = ParentDocumentRetriever(
vectorstore=db,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
# add docs - this creates embeddings for the child chunks and adds
# the related parent chunks to the store
retriever.add_documents(documents)
# create a chatbot chain, conversation-memory is managed externally
qa = ConversationalRetrievalChain.from_llm(
llm=llm,
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
return_generated_question=True,
verbose=True,
)
# count embeddings in chromadb, i.e. get all content vectors and count results
emb_count = len(db.get())
return qa, emb_count
With this small change, we can now use document hierarchies to improve our chatbot’s performance.
Document hierarchies can significantly improve information retrieval, ensuring faster, more reliable, and contextually accurate AI-generated content with reduced errors. LangChain’s ParentDocumentRetriever class implements this strategy, and we only have to change a few lines of code to use it.
Have fun with the bot, extend as you like and let us know if you have any questions or suggestions!

Written By
Alex Bloss - Leiter attempto-Lab. Kreativer Kopf, Innovator, kritischer Denker, Entwickler, praktischer Architekt, CTO, Trend Scout und neugieriger Entdecker mit mehr als zwanzig Jahren Erfahrung.
Using our chat class from the last post we now build a web-app with Streamlit for easy chat with your documents

Unlocking personal conversations with LangChain: building smart Chatbots that understand your documents using Retrieval-Augmented Generation (RAG)